 “Data-Driven Thinking” is written by members of the media community and contains fresh ideas on the digital revolution in media.
“Data-Driven Thinking” is written by members of the media community and contains fresh ideas on the digital revolution in media.
Today’s column is written by Vijoy Gopalakrishnan, principal at the IRI Media Center of Excellence.
This scenario happens all too often in the digital advertising industry: An agency has just conceived and executed a brilliant campaign for a brand. The ROAS is off the charts; there is a measurable uplift in sales and market share.
The agency was confident that it would get kudos and land a new, juicy assignment, but it ended up getting fired instead because the campaign failed to meet the metrics the brand had in place.
What happened?
There is a saying in life: Measure twice, cut once.
But, there is a different saying in the information services industry: Never measure the same thing twice – you may get different results!

All of us do a good job individually to measure things once and in a consistent manner, but collectively we do not. Each partner in the ecosystem, be it the agency, marketer or researcher, brings a different lens to a problem, which can result in different approaches to analyze a given campaign.
While big data and analytics are typically a blessing, it is critical to apply the right data and analytics to gain a true picture of a product’s market position and the impact of a campaign. Equally as important, all partners in the ecosystem must agree on measurement decision points.
Measuring sales lift, in particular, has become a critical metric to gauge the effectiveness of advertising as we expand from measuring click-through rates and impressions to also measuring incremental purchase behavior. Central to the calculus that goes into measuring sales lift is an experimental design, which by definition requires a test and control.
Among marketers, that’s where agreement seems to end. The devil is always in the details as to what constitutes a “true” control, and these details make all the difference in measuring a campaign’s magnitude of success or lack thereof.
By intent, a control group and test group are “identical” in every way except that the test group is subjected to the treatment, or exposure to ads, in our case, while the control group is not. Do you remember when Bill Clinton famously said, “It depends how you define ‘is’”? Similarly, how we define “identical” is where practitioners diverge.
Different matching variable sets have differing sales lift outcomes. In Figure 1, the pre-period matching time frame has been changed to illustrate the point.
Figure 1: Lift results for five sub-sample iterations using 52 weeks, 13 weeks and one year ago match
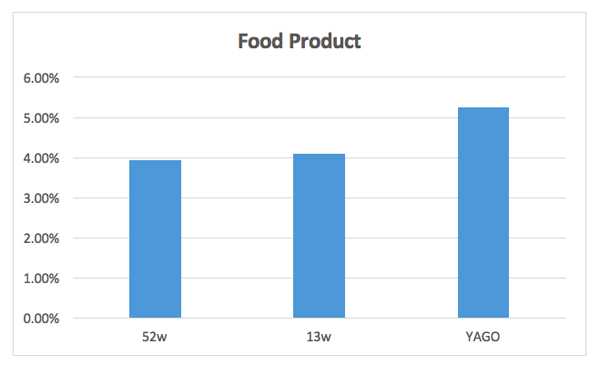
If changing just one variable has such an impact, you can imagine the effect that differences in the selection of multiple matching variables can produce.
We do know from past research that context matters in matching decisions. When analyzing sales lift, which primarily combines an evaluation of media exposure and consumer spend, it stands to reason that any predictors of media exposure and consumer spend would naturally be the superset from which to select our variables.
Variables that are top of mind for matching include:
- Selection of pre-campaign period
- Purchase behavior characteristics
- Demographics
- Media behavior
- Geography
Given the impact these variables have on measurement, standardization therefore is de rigueur to help bring clarity to the discussion as results are compared.
This could potentially lead to a different outcome for the agency mentioned at the beginning of this column. During strategy sessions, brands and their agencies should outline not only the metrics for their ad campaigns, but also the matching variables for the analyses of the control groups. All partners should understand that it is important to be consistent and relevant, so that they are selecting their methodology in a standardized manner that is tailored to the campaign objectives but independent of the campaign outcomes.
By going that extra mile, brands create a single point of truth against which to measure their ad campaigns. That extra step ensures that all parties stay on the same page before, during and after campaigns.
Follow IRI (@iriworldwide) and AdExchanger (@adexchanger) on Twitter.









